
Observability as a function of your threat model
This model attempts to explain the relationship between visibility, observability, detection, and mitigation, which are closely related and important to understand when implementing any information security or cybersecurity program.

Of course, having a model is not the same as having an implementation or an operational capability. And in implementing any program based on a model, it’s very easy to fall into the trap of using the model as a bingo card, treating each component equally and in doing so expending resources in a way that is inefficient or ineffective.
In considering how to approach these four components, it might help to bucket them based on:
- Their primary inputs or drivers
- Any limiting factors that they have in common
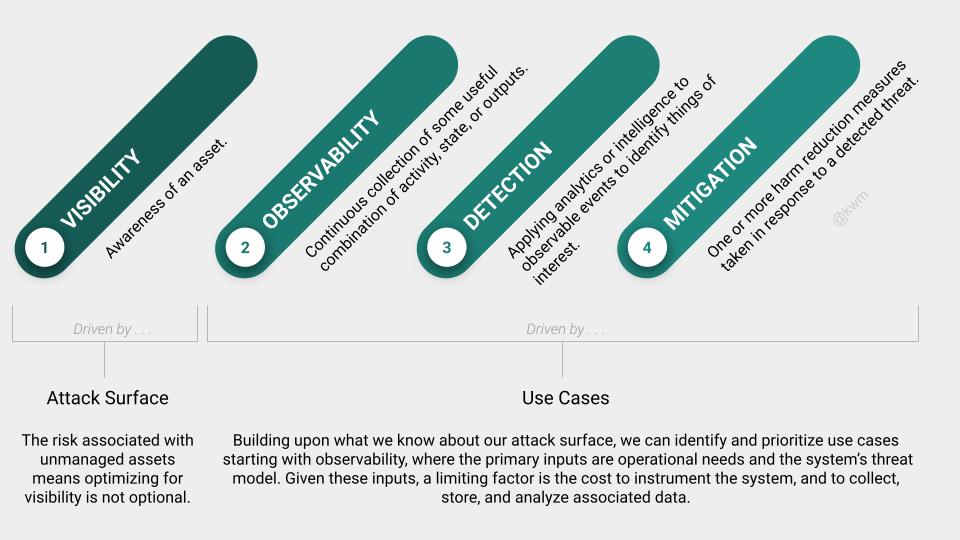
Visibility is a function of your attack surface. Some key inputs here include facilities, networks, infrastructure, and service providers. For each of these, you’re wise to invest in as much visibility as you can. Keep in mind that visibility is knowing that an asset exists, but not necessarily knowing everything about it, how it’s used, or actively monitoring it. You can get a lot of mileage out of good accounting related to identities, devices, applications, etc.
Observability, detection, and mitigation are functions of your use cases. Use cases will include things like the needs of your operational teams, including technical and security operations. They may need more or less of these things in order to maintain systems, detect threats, investigate incidents, and generally mitigate threats or other types of problems.
Observability is the most interesting of the three, because there is so much debate (and marketing) surrounding the types and levels of observability that you need. Of course, a vendor that makes money when you feed it log, security, or other event data–or one who sells you products that produce those signals–is going to make a case that you need as much observability as you can afford. From a security standpoint, I would argue that observability should be driven largely by your threat model, and your understanding of where you need to be in order to observe, detect, and respond effectively to threats.
An implementation of this approach might look something like this:
| Activity | Sample Resources |
|---|---|
| Understand the threats that we face based on the technology that we use, the data that we have, and other factors. | Industry threat reports are great sources of this information: Red Canary’s Threat Detection Report CrowdStrike’s Global Threat Report Mandiant’s M-Trends |
| Identify the techniques that those threats leverage, which can be found using readily available industry reporting. | Leverage the above coupled with other open source reporting, and use MITRE ATT&CK as a model for enumerating specific techniques: https://attack.mitre.org/techniques/enterprise/ |
| From the relevant ATT&CK techniques, identify the data sources that lead to observability of these techniques. Pro tip: You’ll likely find that a small number of data sources have an outsized impact on observability coverage (i.e., a few data sources means that you can see a great percentage of techniques). |
Each ATT&CK technique includes the specific data sources that can be used to observe it: https://attack.mitre.org/datasources/ |
You can go wild with this implementation, but you can also keep it relatively simple and get great results. The guiding principles are that you want to ensure the broadest possible visibility, so that you understand your attack surface and the assets that are at risk, and you want to implement the right level of observability to meet adversaries where they operate, which is where you need to be in order to detect, respond, and mitigate related threats.