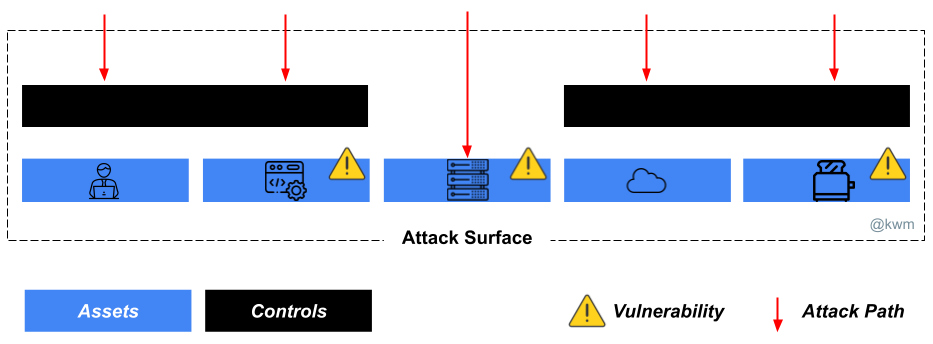
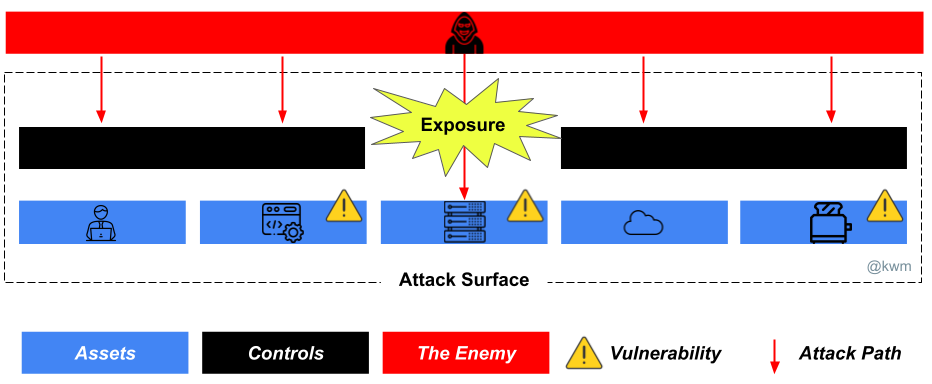
Security software is just software, subject to all of the same problems as any other type of software. And like so much of the software we find in the enterprise, security software has some predictable characteristics:
- Not well understood - Compare how well you understand the platform and behavior of your favorite enterprise security suite to something like Windows, or even lesser-understood platforms like macOS and Linux.
- Lacking observability - And even if observability is possible, see previous statement.
- Poorly managed - So many security products are installed and largely forgotten, save for configuration updates. Out of date versions abound.
- Poorly designed and implemented - Again, security software is just software. And many companies building security products aren’t security companies—they’re software companies, and they invest in product security to the same degree that other software companies do (“just enough”). A special shout out to “enterprise suites”, bloated, complex, frankenstein-esque systems comprising dozens or hundreds of open source and proprietary components that even their creator cannot possibly understand, let alone secure.
Then there’s the kicker:
- Highly privileged, and packed with powerful features - Re-read the list above, and then think about this.
With great power . . .
The phrase “highly privileged, and packed with powerful features” is to some degree a necessary evil, though improved threat modeling and design would go a long way towards reducing the risk to customers.
Endpoint security product features like live response (really, sanctioned rootkits) are like Swiss Army knives for defenders and adversaries alike. Implementing product defaults that alert system owners of its use, strong multi-factor authentication for session initialization, and robust observability are the least that we should expect from a product subsystem that can silently gut an enterprise.

Identity is arguably the one security domain and set of controls that every organization should triple-down on, master, and monitor closely. If you’re managing identity security exceptionally well, you’ve eliminated more attack surface than we appreciate. And for this reason, identity and access management products are prime targets for adversaries and red teams alike. The same is obviously true of more traditional directory services, like Active Directory.
And this is to say nothing of completely bonkers products like TLS intercept devices. These are a terrible, horrible, no good idea for a variety of reasons. The simplest reason is that anything of extraordinary value will eventually end up in the wrong hands. And in the wrong hands, security products that undermine foundational security and privacy controls (e.g., encryption) will absolutely gut your enterprise.
. . . comes great opportunity
For adversaries, security products will always be enticing and high value targets. A zero day in a security product might not have the same reach as one targeting Windows or macOS, but adversaries can and do get significant mileage out of exploitation or abuse of security tooling.
So, not only are these security products part of your attack surface, they carry some extraordinary risk. The likelihood of exploitation may be lower than that of most widespread platforms and software, but when it happens, the impact can be catastrophic.
I do believe that computing platforms are getting more secure overall. The trend towards app store-style platforms lends to more restrictive default configurations, making it far more costly to introduce malicious software. And other successful technical controls continue to move upstream and are included by default in most end user and production computing platforms. But because security products are uniquely valuable, and because we’re taking away attack surface in these other areas, we’ll continue to see adversaries do an end run around traditional targets to go after identity providers and other security products instead.
Vulnerabilities.
One way that the shortcomings I list at the start—and there’s shared responsibility for these amongst vendors and users alike—come home to roost is vulnerabilities. Paying attention to software vulnerabilities in security products is particularly useful, as it may be the most objective means of understanding how often adversaries are weaponizing security products and using them to harm us.
Here are some of the receipts from last year alone, courtesy of CISA’s list of 2022 Top Routinely Exploited Vulnerabilities:
- CVE-2018-13379 - Fortinet FortiOS SSL VPN Path Traversal Vulnerability CVE-2021-20016 - SonicWall SSLVPN SMA100 SQL Injection Vulnerability
- CVE-2021-20021 - SonicWall Email Security Improper Privilege Management Vulnerability
- CVE-2021-20038 - SonicWall SMA 100 Appliances Stack-Based Buffer Overflow Vulnerability
- CVE-2022-1388 - F5 BIG-IP Missing Authentication Vulnerability
- CVE-2022-40684 - Fortinet Multiple Products Authentication Bypass Vulnerability
- CVE-2022-42475 - Fortinet FortiOS Heap-Based Buffer Overflow Vulnerability
I only examined the broader list (which surpassed the 1000 exploit mark as of September 2023), long enough to make my point. But there are plenty more:
- CVE-2020-5902 - F5 BIG-IP Traffic Management User Interface (TMUI) Remote Code Execution Vulnerability
- CVE-2022-41328 - Fortinet FortiOS Path Traversal Vulnerability
- CVE-2023-2868 - Barracuda Networks ESG Appliance Improper Input Validation Vulnerability
- CVE-2023-20269 - Cisco Adaptive Security Appliance and Firepower Threat Defense Unauthorized Access Vulnerability
- CVE-2023-27532 - Veeam Backup & Replication Cloud Connect Missing Authentication for Critical Function Vulnerability
- CVE-2023-27997 - Fortinet FortiOS and FortiProxy SSL-VPN Heap-Based Buffer Overflow Vulnerability
What do we do about it?
For starters, vendors must acknowledge that customers pay money for security products to reduce risk, but that their solutions often introduce new, significant risks. Threat model, design, build, and configure (by default!) accordingly.
On the enterprise side, CISA’s work to lower the vulnerability management noise floor is providing organizations with the thing that vendor solutions largely have not: The list of things you’d better patch right now. So, even if you don’t have or can’t afford a vulnerability management solution:
- Sign up for CISA advisories
- Patch top exploited vulnerabilities first
- Patch known exploited vulnerabilities in all of your free time
Lastly, don’t just rely on your security products to monitor the rest of your attack surface. Treat your security products as a critical cross-section of your attack surface, and monitor it as closely as you monitor anything else.
Discussion on LinkedIn