
Introducing Atomic Scorecard: A test tracking tool for ATT&CK + Atomic Red Team
If you haven’t tested it, it doesn’t work. This foundational thesis drove the creation of Atomic Red Team and the concept of atomic testing for cybersecurity teams. One key lesson from its adoption: testing is more like exercise than an exam. Small, regular tests pay far larger dividends than annual or “big bang” red team engagements.
To encourage ongoing testing, I’ve long maintained a crude spreadsheet for tracking, scoring, and measuring test outcomes. I’ve now converted it into a web-based tool.
What is it?
At its core, Atomic Scorecard is a simple system of record for atomic tests. Like Atomic Red Team, it uses MITRE ATT&CK as the foundation, but it overlays industry threat intelligence, and naturally makes it easy to find atomic tests relevant to each technique.
No account is needed. There’s no database or other backend. None of your test data is stored.
Intelligence-driven prioritization
The most common ATT&CK hangup is that it’s expansive and hard to know where to start. Few organizations have enough threat intelligence to know which techniques matter most. And even then, prevalence data is more reliable than first-party intel alone. Not all techniques are created equal, and from Red Canary’s 2026 Threat Detection Report:
[A] relatively small number of techniques play a role in a disproportionately large number of detections . . . [O]ver the last five years, we’ve detected at least one of the 10 most prevalent techniques in 46 percent of all detections. Over the same time period, we detected at least one of the top 20 techniques in 63 percent of detections.
By default, the tool’s technique rankings are drawn from Red Canary’s annual report, observed across thousands of companies of every size and industry. Also included are Mandiant’s top techniques, sub-techniques, and a complete M-Trends ATT&CK appendix by tactic:
- Red Canary 2026 Threat Detection Report (default)
- Mandiant M-Trends 2026 Top Techniques
- Mandiant M-Trends 2026 Top Sub-Techniques
- Mandiant M-Trends 2026 Complete ATT&CK appendix (top techniques and sub-techniques for every ATT&CK tactic)
You can also upload custom rankings to reflect your organization’s specific threat landscape.
Integration of ATT&CK + Atomic Red Team
The tool is built to move you from documentation to execution in seconds:
- Every technique is linked directly to the official MITRE ATT&CK documentation
- For any technique where an Atomic Red Team test exists, a clickable logo appears that takes you directly to tests that correspond to that technique
I recommend using the Invoke-AtomicRedTeam framework, which makes test selection, execution, and optionally things like prerequisites and cleanup fast and easy.
Tracking and reporting
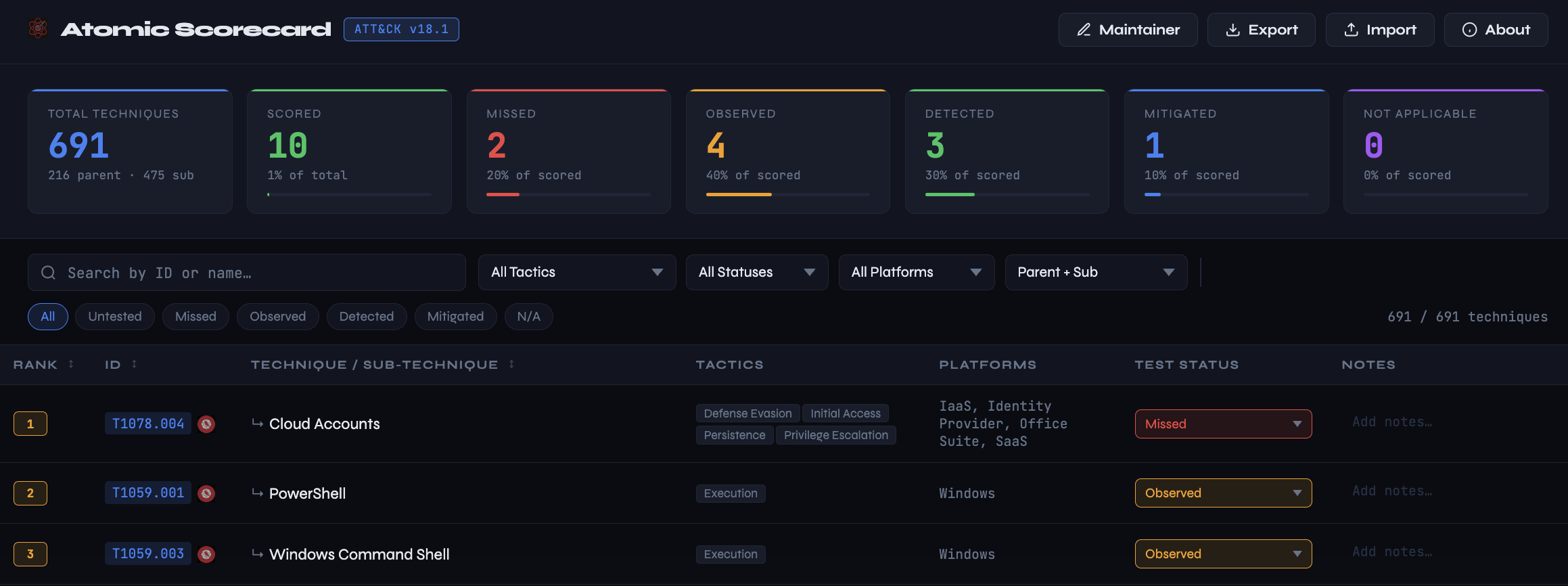
Testing is less impactful if you don’t record and measure the results. For every technique that you test, you can categorize test outcomes into one of four states:
- Missed: The attack went completely unnoticed.
- Observed: You saw the telemetry, but no alert was triggered.
- Detected: You were alerted to the activity.
- Mitigated: The attack was blocked or interdicted by existing controls.
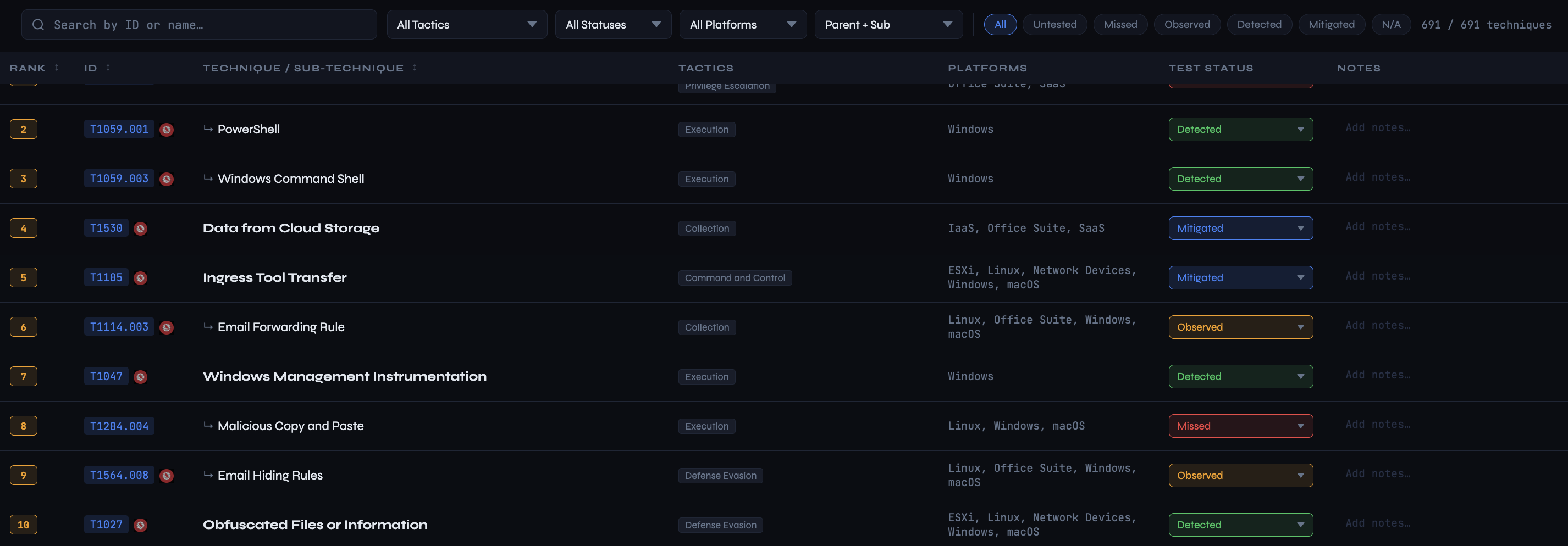
You can also add notes related to a given technique, since a simple status may not capture important context, or mark a technique as not applicable to your environment.
A simple dashboard at the top makes it easy to see your test coverage and outcomes.

Flexibility and customization
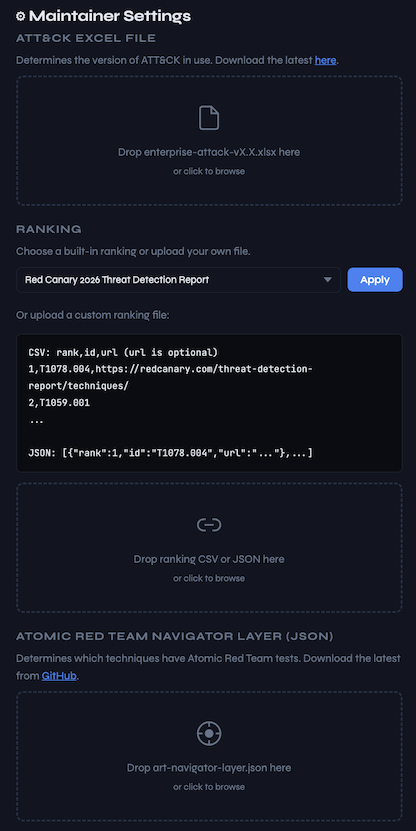
To ensure this tool stays relevant as ATT&CK, Atomic Red Team, and your priorities evolve, the Maintainer tools allow you to update or customize:
- ATT&CK version
- Atomic Red Team coverage
- Technique ranking
There’s also a simple JSON-based backup and restore capability. Export your entire project as a JSON structure at any time. When you’re ready to resume, just import the file and pick up exactly where you left off.
Share your feedback
If there’s something you’d like to see that isn’t included, something isn’t working, or if you’d just like to send some feedback, you can reach me via email: kwm @ this domain.
Ready to start testing? Give it a go at https://atomicscorecard.com