This article is adapted from a presentation (charts + talk track) I’ve maintained over the years as a tool to help myself and others understand how technology adoption drives the work we do in cybersecurity, and where we are in the technology adoption cycle at any given time. Charts revised late 2023.
Cybersecurity isn’t an isolated problem space. Cybersecurity as a discipline exists to safeguard data, typically by securing the underlying technologies used to access it. And because adoption of new technologies will always outpace our ability to secure them to the degree we’d like, cybersecurity is an inherently unsolvable and cyclical problem space.
This is one reason I enjoy studying cybersecurity and risk management maturity models. “Better at security today than we were yesterday” is an admirable mantra for any cybersecurity team. However, one thing I’ve learned about this type of modeling is that it helps us understand and improve upon the work, but typically doesn’t help us understand the inputs—technologies adopted by the business and users—that ultimately drive it.
Technology adoption cycle overview
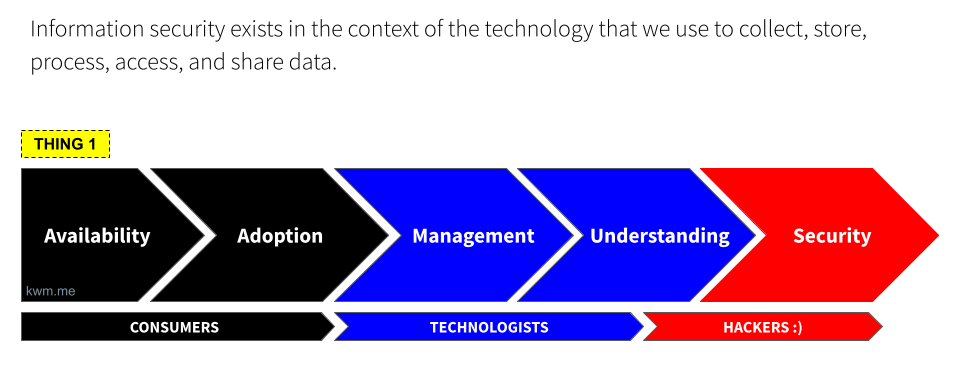
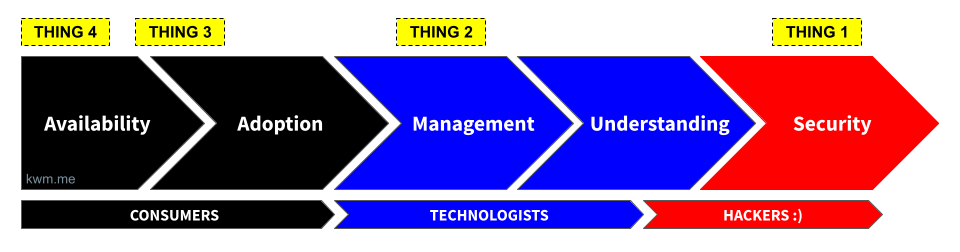
This model focuses instead on where a given technology is on its journey from initial availability through to the low-level understanding required to effectively secure it. The primary use case is planning and alignment within a given organization, based on the technology stack and security controls at a point in time. By plotting key technologies relative to one another and along a continuum, it can be easier to track progress, maturity, depth of understanding, and more.
Availability
First, technology becomes available to users. The major mobile app stores alone publish somewhere north of 1,000 new applications daily, and this is to say nothing of websites, SaaS applications, and other services beyond the mobile ecosystem. The proliferation of new software in particular is staggering, and generative artificial intelligence (GenAI) is driving the cost and time required to launch new applications and services down by the day.
Here it’s also worth noting that most cybersecurity practitioners are employed to protect businesses, but there’s no meaningful or predictable delineation between “business” and “consumer” technology. The prevalence of “bring your own device” (BYOD) is a clear indicator of this phenomenon, as are the countless businesses that leverage social media platforms, individuals who keep personal appointments on their work calendar, and more.
Adoption
Naturally, users start to adopt these new technologies. And not always because they should, but because they can.
The launch of the first iPhone is the canonical example of this phenomenon: Overnight, seemingly everyone had an iPhone. And while enterprises could ignore some noisy software engineers clamoring for access to corporate email and productivity apps on their new iPhones, they couldn’t ignore the CEO.
Adoption happens, and because it’s largely a function of availabilty coupled with consumer or user demand, if often occurs without the broader technology and/or security team’s awareness.
Management
Largely in response to adoption, enterprises make some attempt to manage technology. That is, to get a handle on who’s using it, how, and for what. Early “management” may be little more than a crude accounting of who’s using the tech, and an attempt to control the blast radius should something go wrong.
Early attempts to manage a new piece of technology will usually focus on the “bookends”: How the software is accessed (e.g., via identity and access management), and how the software is managed (e.g., whether it can be installed, or by removing it if unauthorized). For a piece of technology with sufficient access to sensitive data, these are imperfect but important first steps towards management.
Understanding
Once we dedicate resources to managing a given technology, our understanding of the technology improves, out of some mix of necessity and curiosity. This is where a lot of wildly valuable automation, control, and security tools (often free and/or open source) begin to materialize.
Many of the leading solutions in the device management, monitoring, and myriad other spaces were born during this evolution from basic management of an emerging technology to a better, deeper, and more meaningful understanding of how it’s being used, what it’s accessing and how, and ultimately how it can be better monitored and/or controlled.
Security
We can’t secure what we don’t understand.
Only once a technology becomes well understood will enterprises and controls mature to effectively secure it. This is where hackers and the cybersecurity community shine. Taking a technology from “we can keep a lid on it” to “we know more about this than the people who made it” is a hallmark of hacker culture and the cybersecurity industry that often pays its bills.
We’re still not “done”, but technology that reaches this phase is generally well studied and a robust set of controls are available. It also stands to reason that these technologies also have a well developed threat model and may be frequently targeted by adversaries, who are naturally interested in widely adopted, entrenched technologies.
An illustrative look
Plotting the modern tech stack
Here’s a illustration of what this looks like in practice, using a common set of technologies:
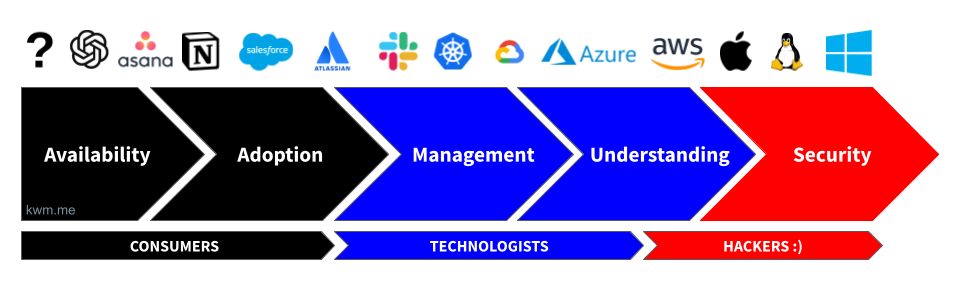
In general, technologies farthest to the “left” will be characterized by one or more of the following:
- The inner workings of these technologies aren’t well understood and/or documented
- Threat models are not widely understood or accepted
- Observability may be lacking (i.e., APIs or other means of accessing access, usage, and security event data aren’t robust, and sometimes do not exist at all)
- Lack of robust built-in or third-party security controls
Grouping technologies by family or type
This same phenomenon also applies to types of technology. In fact, determining whether we’re dealing with an evolutionary (e.g., our 1,001st project management tool) or revolutionary (e.g., ChatGPT) technology is how we spot a leading indicator that we’ll have a lot of net new work to do.
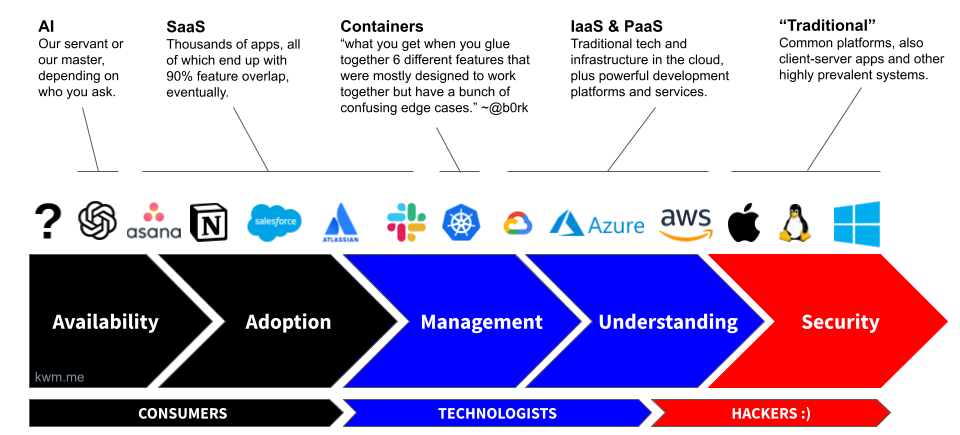
As you reflect on the above illustrations, note a few things:
- It took us decades to do a passable job of securing the “traditional” technologies on this chart (Windows, macOS, and Linux).
- In less than one decade, most everything else on this chart was introduced, and each time the cycle began anew.
- In a single year (2023), the widespread adoption of GenAI put that technology on the fast track through this cycle, but also had the rare side-effect of causing us to reevaluate most existing technologies, as GenAI was adopted by end users and much of our existing technology stack simultaneously
Takeaway: Technology adoption will always outpace security
The takeaway here is not how we adopt technology, but that technology adoption will always outpace security, and this is best thought of as a primitive and not a failure.
For every technology that progresses through this cycle, expect countless new inputs. And expect that a problem that we’ve solved for in the context of a particular technology or domain will need to be revisited and implemented in new ways, either because technology or assumptions change, but also because we work in an adversarial industry, and the enemy never rests.
Using this model
Hopefully this model is useful, irrespective of where you are in your cybersecurity journey.
For those looking to enter the field, it may help you understand what to expect.
For those actively involved in cybersecurity, either as dedicated professionals or as one of the millions of technologies for whom cybersecurity is “other duties as assigned”, it can be a useful framework for visualizing and/or forecasting technologies that impact your work.
And in general, it highlights the single biggest externality affecting our profession. Understanding that this is how it works may help you avoid some of the burnout and nihilism that plagues our industry, as many practitioners strive for “perfect” or “done”, rather than striving for balance given that the cycle is supposed to continue.