Cybersecurity stat of the day: The average delta (in years) between CVE assignment and addition to the CISA Known Exploited Vulnerability (KEV) catalog is 2.8 years. 🤯
January 14, 2025

Cybersecurity stat of the day: The average delta (in years) between CVE assignment and addition to the CISA Known Exploited Vulnerability (KEV) catalog is 2.8 years. 🤯
January 14, 2025
I’m a huge fan of Objective-See, Patrick Wardle’s non-profit organization, and the arsenal of invaluable macOS secuirty tools he provides.
I use Patrick’s OverSight product to monitor camera and microphone activity. By default, OverSight uses notifications to alert you to camera or microphone activity (e.g., when an application activates these devices). In addition to these notifications, I also want to write these events to a log.
OverSight doesn’t have a built-in logging feature, but it does allow you to execute a script when an event is triggered. The Pass Arguments option conveniently passes useful inputs to your script.
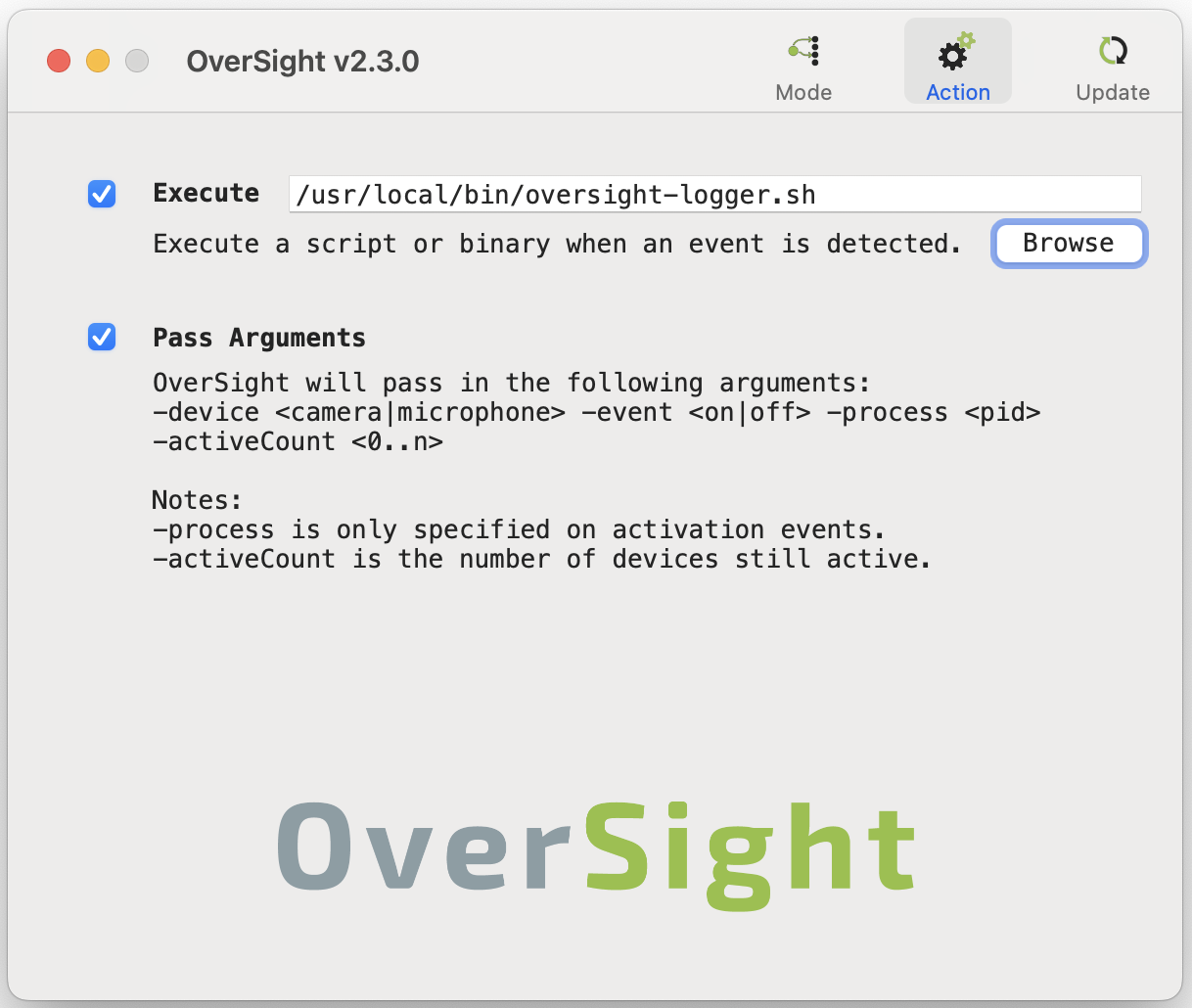
oversight-logger is a simple shell script that uses the provided inputs to write sensible log entries when camera or microphone events take place. The only substantive functionality is a pair of functions that look up the process path and process username based on the PID. The resulting log entries will look like this:
2024-12-08 13:45:03 /Applications/zoom.us.app/Contents/MacOS/zoom.us username -device microphone -event on -process 99681 -activeCount 1
2024-12-08 13:45:08 /Applications/zoom.us.app/Contents/MacOS/zoom.us username -device camera -event on -process 99681 -activeCount 2
2024-12-08 13:45:12 NULL NULL -device microphone -event off -activeCount 1
2024-12-08 13:45:12 NULL NULL -device camera -event off -activeCount 0
I’ve been really interested in how AI engines will impact traditional content discovery models. A key hypothesis is that content creators will reduce time-to-citation by:
Meanwhile, it feels as though AI engines will race to achieve “query capture,” the flywheel of user sentiment, trends, and interests that fuels first-party innovation, third-party data sales, and advertising.
Perplexity pioneered search with citations, but I suspect the release of ChatGPT search will accelerate this particular land grab:
The search model is a fine-tuned version of GPT-4o, post-trained using novel synthetic data generation techniques, including distilling outputs from OpenAI o1-preview. ChatGPT search leverages third-party search providers, as well as content provided directly by our partners, to provide the information users are looking for.
Interesting to think about how “partners” might expand beyond larger publishers, who exist primarily as a source of training data for the engine, but get the benefit of some amount of prioritized discovery and presentation to users. Maybe smaller publishers and/or individuals will begin seeding AI engines with content as a means of getting discovered?
Great reporting by Brian Krebs:
Not long ago, the ability to digitally track someone’s daily movements just by knowing their home address, employer, or place of worship was considered a dangerous power that should remain only within the purview of nation states. But a new lawsuit in a likely constitutional battle over a New Jersey privacy law shows that anyone can now access this capability, thanks to a proliferation of commercial services that hoover up the digital exhaust emitted by widely-used mobile apps and websites.
99.9% of us shouldn’t worry about the NSA, but 100% of us should worry about marketing (MarTech) and advertising (AdTech).
The Government™ has tremendous resources, but is also a massive bureaucracy saddled with myriad political, legal, and resource constraints. So, while the national technical means (read: spy tech) exist to hoover up and store limitless amounts of data, what they can practically do to and with that data is subject to some limits. Most notably, it’s not in the intelligence community’s interest to try to look at everyone.
Precisely the opposite is true of marketing and advertising. For every human with a dollar to their name, now or in the future, there is someone who wants to sell them something.
To borrow some intelligence jargon, the “targeting list” is effectively the whole of the developed world, and there is so much unregulated signal that two things are true:
Virtually any entity within the ecosystem can truthfully say things like “we don’t share X with Y” or “we use privacy-preserving consumer identifiers”
Virtually any entity within the ecosystem can piece together enough “anonymized” data to associate a name, place, and much more to any identifier, if they choose
I uploaded The End of Advertising along with my commentary into NotebookLM and asked it to generate a brief discussion between two hosts. The results are impressive, in particular the aspects of the topic that aren’t covered by either the original text or my own.
October 21, 2024